社区项目开发数据库准备工作
本文共 253 字,大约阅读时间需要 1 分钟。
首先需要创建一个数据库,并建表导入数据,为后续操作做准备,这一步通常比较繁琐,但在实际项目开发中,除了DBA外,一般很少由开发人员建表
下面是简单的SQL语句
SHOW DATABASES;CREATE DATABASE community;SHOW DATABASES;USE community;SHOW TABLES;
表的创建和数据的导入,使用了外面的两个SQL脚本
数据库由以下几张表构成

其中user用户表的信息如下
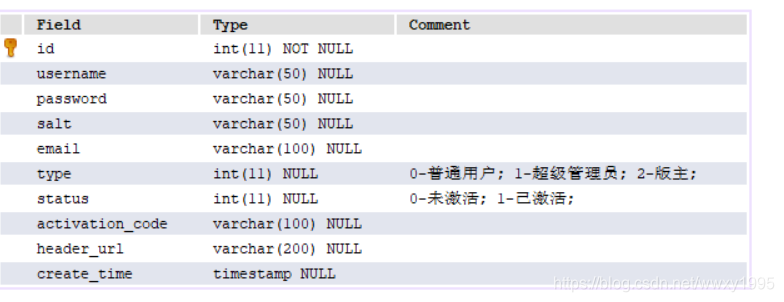
消息表如下

下一步,配置MyBatts,完成利用Java代码高效的操作数据库
转载地址:http://bfmv.baihongyu.com/
你可能感兴趣的文章
mysql部署错误
查看>>
MySQL锁与脏读、不可重复读、幻读详解
查看>>
mysql锁机制,主从复制
查看>>
Mysql锁机制,行锁表锁
查看>>
MySQL集群解决方案(4):负载均衡
查看>>
mysql面试题学校三表查询_mysql三表查询分组后取每组最大值,mysql面试题。
查看>>
Mysql面试题精选
查看>>
MySQL面试题集锦
查看>>
mysql颠覆实战笔记(八)--mysql的自定义异常处理怎么破
查看>>
mysql驱动、durid、mybatis之间的关系
查看>>
mysql驱动支持中文_mysql 驱动包-Go语言中文社区
查看>>
MySQL高可用切换_(5.9)mysql高可用系列——正常主从切换测试
查看>>
MySQL高可用解决方案详解
查看>>
MYSQL高可用集群MHA架构
查看>>
MySQL高级-MySQL并发参数调整
查看>>
MySQL高级-MySQL查询缓存优化
查看>>
MySQL高级-MySQL锁
查看>>
MySQL高级-SQL优化步骤
查看>>
MySQL高级-内存管理及优化
查看>>
MySQL高级-视图
查看>>